Why is Redis Fast?
Redis is fast for in-memory data storage. Its speed has made it popular for caching, session storage, and real-time analytics. But what gives Redis its blazing speed? Let’s explore:
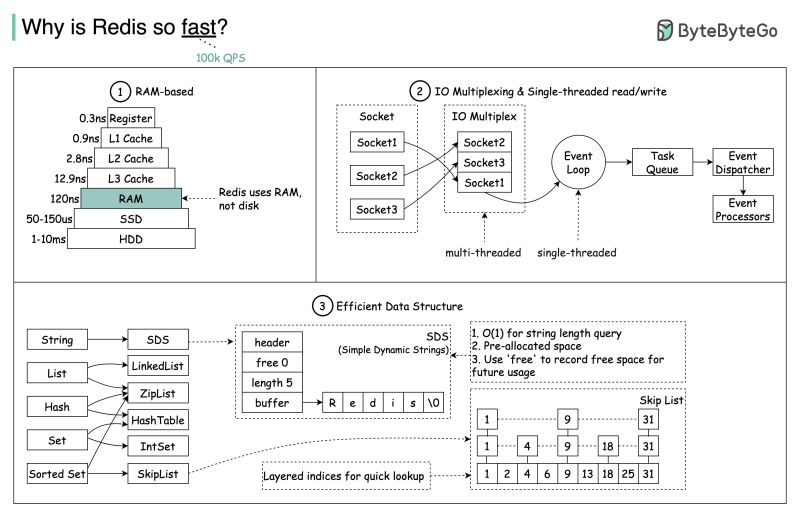
𝗥𝗔𝗠-𝗕𝗮𝘀𝗲𝗱 𝗦𝘁𝗼𝗿𝗮𝗴𝗲
At its core, Redis primarily uses main memory for storing data. Accessing data from RAM is orders of magnitude faster than from disk. This is a major reason for Redis’s speed.
However, RAM is volatile. To persist data, Redis supports disk snapshots and append-only file logging. This combines RAM’s performance with disk’s permanence.
There is a tradeoff though - recovery from disk is slow. If a Redis instance fails, restarting from disk can be slow compared to failing over to a replica instance fully in memory. So while Redis offers durability via disk, it comes at the cost of slower recovery.
A better solution is Redis replication. With a synchronized replica kept in memory, failover is instant with no rehydration. This maintains speed and near-instant recovery.
𝗜𝗢 𝗠𝘂𝗹𝘁𝗶𝗽𝗹𝗲𝘅𝗶𝗻𝗴 & 𝗦𝗶𝗻𝗴𝗹𝗲-𝘁𝗵𝗿𝗲𝗮𝗱𝗲𝗱 𝗥𝗲𝗮𝗱/𝗪𝗿𝗶𝘁𝗲
Redis uses an event-driven, single-threaded model for its core operations. A main event loop handles all client requests and data operations sequentially. This single-threaded execution avoids context switching and synchronization overhead typical of multi-threaded systems.
Redis uses non-blocking I/O to handle multiple connections asynchronously. This allows it to support many client connections with very low overhead,
Redis does leverage threading in certain areas:
- Background tasks like taking snapshots. - I/O threads are used for certain operations. - Modules can use threads. - Since Redis 6.0, it supports multi-threaded I/O for network communication, improving performance on multi-core systems.
Redis also uses pipelining for high throughput. Clients pipeline commands without waiting for each response. This allows more efficient network round trips, boosting overall performance.
𝗘𝗳𝗳𝗶𝗰𝗶𝗲𝗻𝘁 𝗗𝗮𝘁𝗮 𝗦𝘁𝗿𝘂𝗰𝘁𝘂𝗿𝗲𝘀
Redis supports various optimized data structures, from linked lists, zip lists, and skip lists to sets, hashes, and sorted sets, among others. Each is carefully designed for specific use cases for quick and efficient data access.
Over to you: With Redis now supporting some multi-threading, how should we configure it to fully utilize all the CPU cores of modern hardware when deploying in production?