What is Retrieval-Augmented Generation (RAG)?
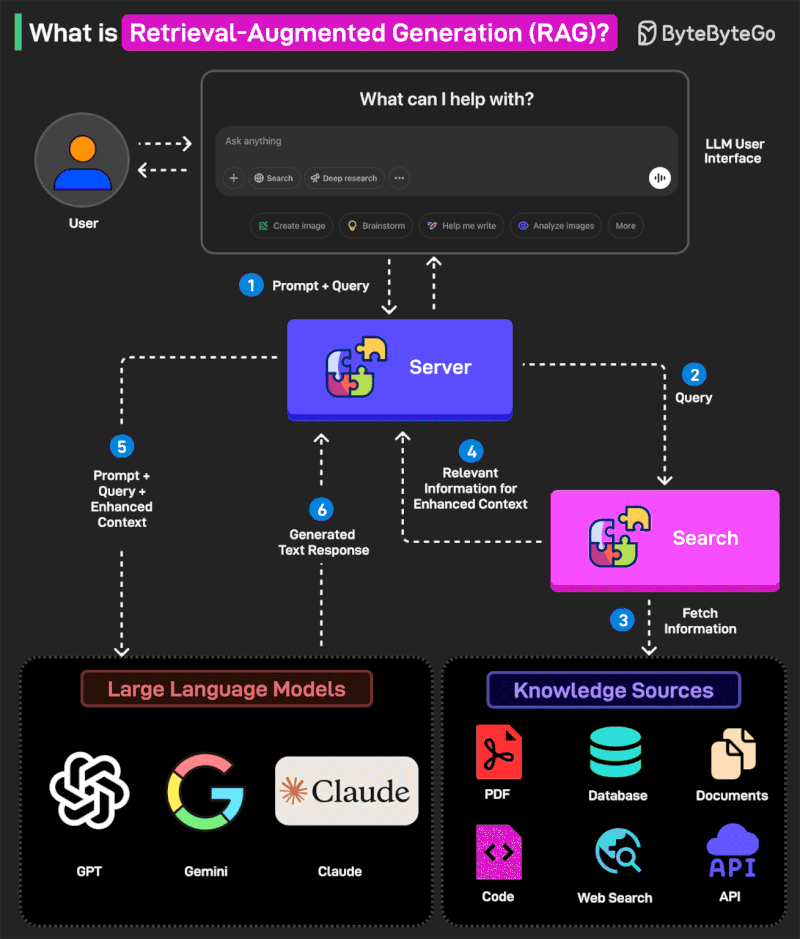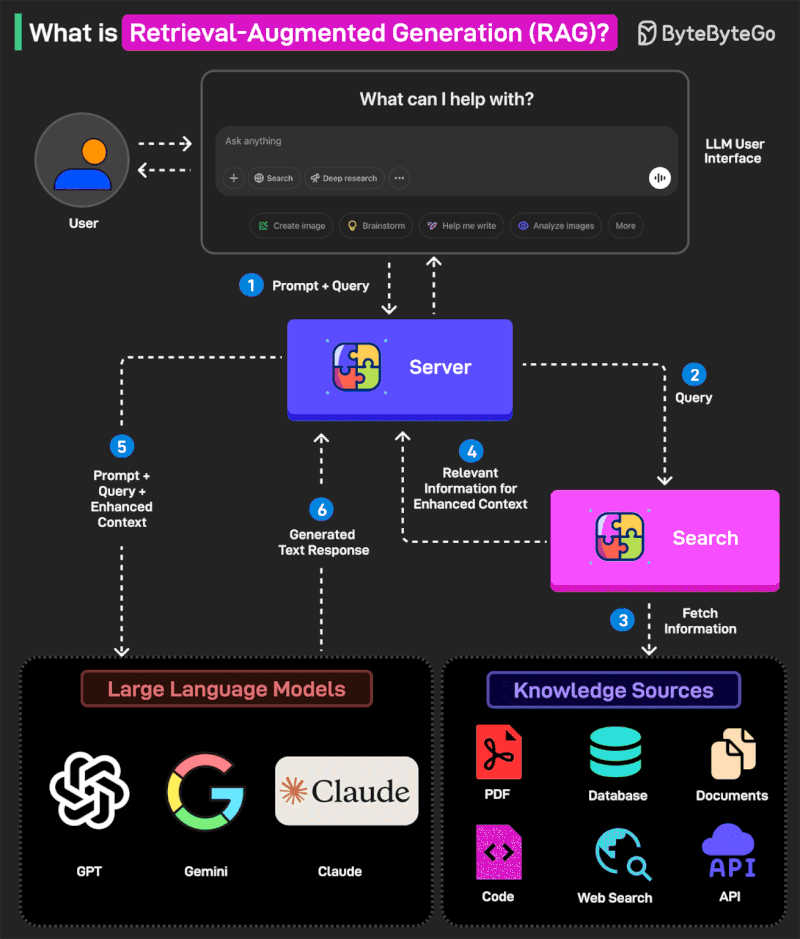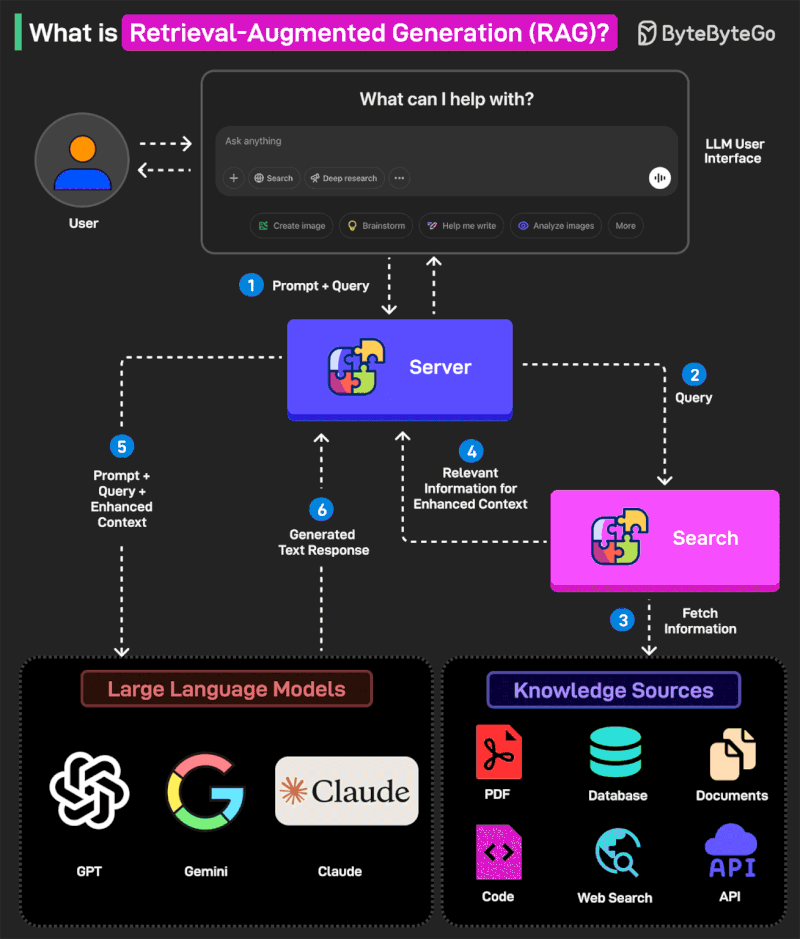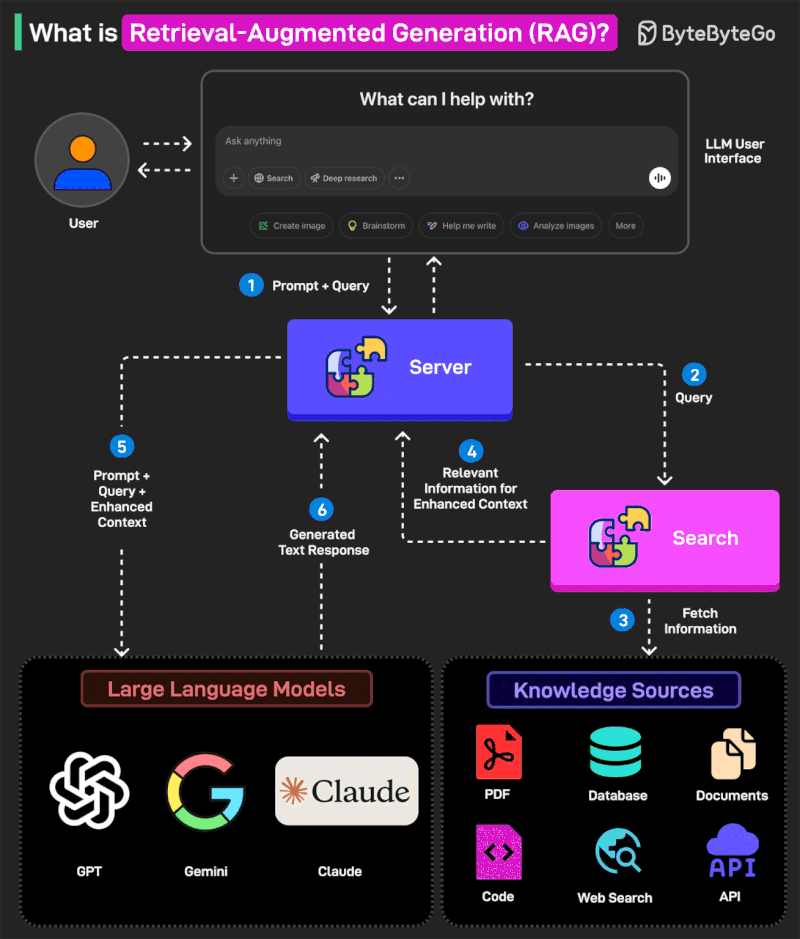
RAG augments LLM outputs by referencing authoritative knowledge bases outside the model’s training data before generating responses.
This approach extends LLM capabilities to specialized domains without requiring expensive retraining or fine-tuning.
How RAG Works:
-
Prompt + Query The user submits a prompt through the LLM interface. The server converts this query into a vector representation.
-
Query The vectorized query is sent to the search system.
-
Fetch Information The search system retrieves relevant information from various knowledge sources—PDFs, databases, documents, code repositories, web search, and APIs.
-
Relevant Information for Enhanced Context The fetched information is sent back to the RAG model to augment the original query.
-
Prompt + Query + Enhanced Context The system combines the original user input with the retrieved information, creating an enriched prompt that’s sent to the LLM endpoint (GPT, Claude, Gemini, etc.).
-
Generated Text Response The LLM generates a contextually-aware answer based on the enhanced context and returns it to the user.
This architecture solves the knowledge cutoff problem while maintaining the LLM’s conversational abilities and reasoning power.